Serie: Show&Tell
Wenn es uns an irgendwas nicht fehlt auf dieser Welt, sind es Daten. Damit lösen wir Probleme und optimieren bestehende. Wir sammeln sie an jedem Sensor, den wir auslösen, bei jedem unserer Schritte, die wir gehen, über alle Vorlieben, die wir haben. Das optimiert nicht nur Probleme, sondern stärkt auch Misstrauen, Ungewissenheit, Manipulation und Überforderung. Der Journalismus, in all seinen Formen, versucht diese Daten einzuordnen.
In dieser Serie blicken wir auf verschiede digitale und analoge Projekte, die genau das versuchen. Jeder Blick ist eine Anerkennung der Arbeit, versucht aber auch, mit neuen Ideen zu punkten.

TLDR;
Dieser Artikel analysiert die Plattform Pharmagelder.ch, die Geldflüsse der Pharmaindustrie in der Schweiz transparent macht. Es werden Verbesserungspotenziale in der Datenvisualisierung aufgezeigt und Lösungsansätze skizziert, um die Übersichtlichkeit und Verständlichkeit der Daten für Konsumenten zu erhöhen.
Transparenz sichtbar machen
Seit rund zehn Jahren ist der Schweizer Pharma-Kooperations-Kodex in Kraft. Ein Regelwerk, das die Pharmaindustrie in der Schweiz verpflichtet, ihre Geldleistungen an Fachpersonen und Organisationen sichtbar zu machen. Wie so oft, wird Transparenz in Unternehmen stiefmütterlich behandelt. Für das Unternehmen ist es naheliegend, Transparenz so intransparent wie möglich zu gestalten, vor allem und auch wenn sie vom Gesetz dazu verpflichtet werden. Hier setzt die Plattform Pharmagelder.ch an. Ein Netzwerk von Journalist:Innen hat sich durch die unübersichtlichen Transparenzbekundungen der Pharmaunternehmen gewühlt, um Spenden, Sponsoring und sonstige Geldflüsse an die behandelnde Medizin, Fachpersonen, und Organisationen für die Verbraucher sichtbar zu machen.
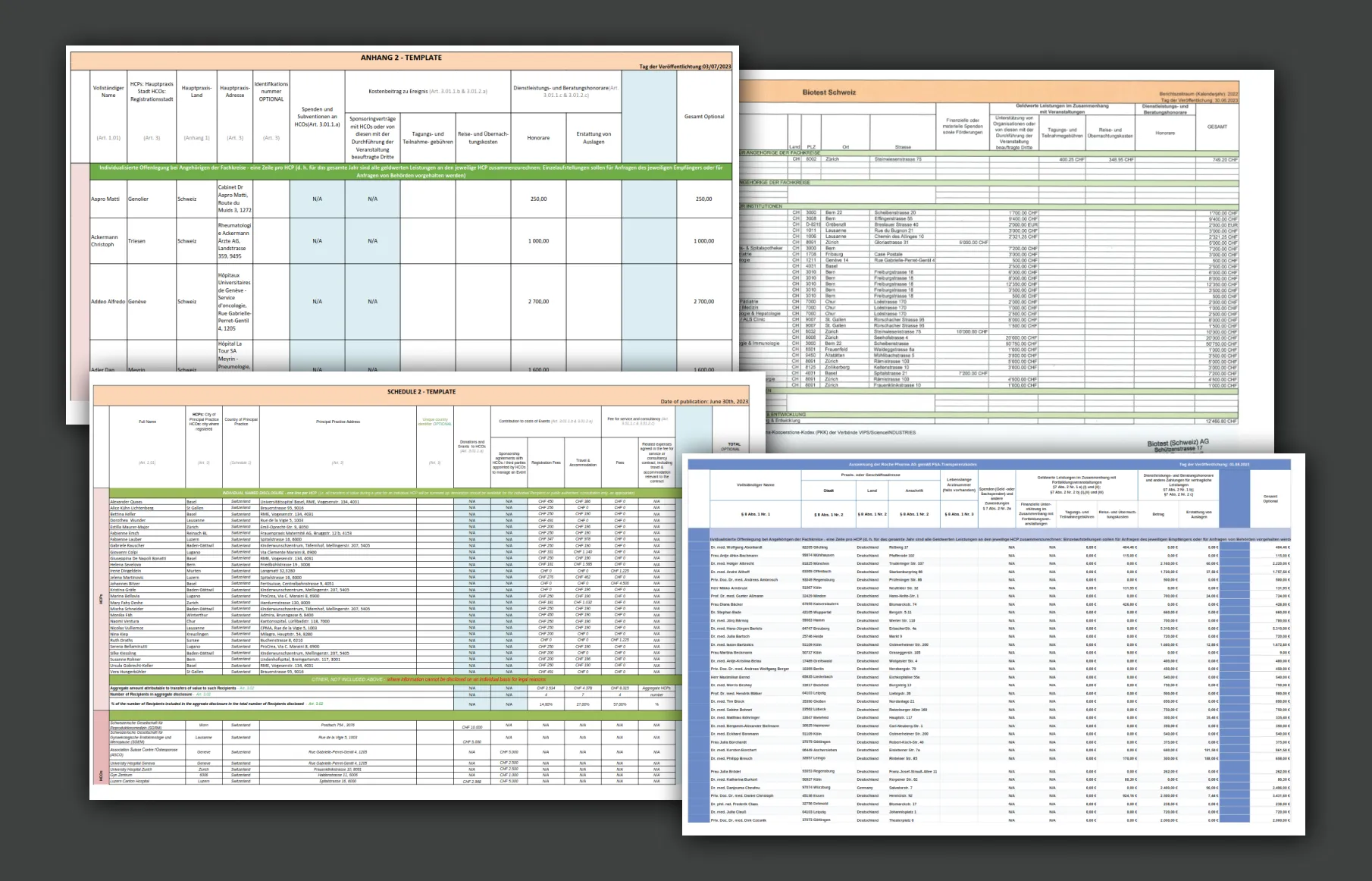 Folge des Pharma-Kooperations-Kodex (PKK) – Transparenzberichte unübersichtlich und schlecht strukturiert.
Folge des Pharma-Kooperations-Kodex (PKK) – Transparenzberichte unübersichtlich und schlecht strukturiert.
Ich sehe was, was du nicht siehst
Der erste Eindruck der Plattform pharmagelder.ch ist ernüchternd. Viel Text, viel Rechtfertigung, wenig Daten. Scheinbar versteckt die Plattform die Daten, obwohl sie damit angetreten ist, Licht ins Dunkle der Pharmagelder zu bringen. Ich bin gezwungen, eine Postleitzahl, einen Ort oder einen Namen einzugeben, also ein klassische Suche zu starten. Leider fehlt mir der Überblick über Zahlungen, Mediziner:Innen oder Pharmaunternehmen. Kein Dashboard, keine Grafiken - nur Text und eine Suchmaske.
Intuitiv suche ich nach meiner Hausärztin. Sie nahm Geld von der Pharmaindustrie. Ganze 100 Schweizer Franken. Das Vertrauen ist nun dadurch nicht nachhaltig gestört, dennoch weckt es die Neugier. Mehr leider nicht.

Ein Link auf Novo Nordisk, den Pharmariesen, der durch Ozempic und Wegovy in den letzten Jahren Umsatzrekorde bricht, offenbart erste interessante Information zum Datensatz. Dutzende Millionen vergeben Novo Nordisk und weitere Pharmaunternehmen in der Schweiz jährlich an Gesundheits-Organisationen, Forschung und Medizin. Detailliert wird die Plattform erst in einem verlinkten Artikel, nicht aber im Datensatz. Nur wie steht das Pharmaunternehmen mit seinen Zahlung im Vergleich zur Konkurrenz? Wieviel ging im vergangen Jahr an Organisationen oder in die Forschung? Gibt es Tendenzen oder gar einen Trend zu beobachten?
Nach der kurzen Tour de Plattform können wir einige Fragen beantworten:
- Die Fülle an Daten ist gross. Suchfunktion und Datenbank funktionieren bestens. Die Daten sind sehr gut aggregiert.
- Detaillierte und/oder kontextuelle Informationen zum Datensatz sind spärlich oder hinter Links versteckt.
- Der Plattform fehlt schlicht Übersicht. Ein kleines Dashboard, eine Visualisierung oder wenigstens einordnende Texten hätten Pharmagelder.ch gut getan.
Wer eine aufwendige und saubere Datenrecherche hinter einer Suchmaske versteckt, verschenkt Potenzial. Die Plattform verpasst es dadurch, die Zielgruppe an der Hand zu nehmen und sie zum Datenschatz zu führen.
Vielleicht war die Intention hinter der Plattform weniger die journalischtische Aufklärung der Konsument:In, als mehr der Versuch,diese zu bemächtigen, eigene Erkenntnisse zu erarbeiten. Eine valide Strategie, nur könnte sie hier mit Suchfiltern und Hinweisen zu Suchbegriffen den Nutzer noch effizienter unterstützen.
Zum Zeichenbrett
Die saubere Datenaufbereitung macht es uns glücklicherweise leicht, zumindest ein Gefühl für den Datenumfang zu entwickeln. Die Suchmaske und Verlinkungen sind für die Suche gut geeignet.

- Der Zeitraum der Datenerfassung umfasst die Jahre 2015 bis 2022
- Die Geldflüsse werden in folgende Kategorien unterteilt:
- Spenden
- Sponsoring
- Kongress-/Tagungsgebühren
- Reise-/Übernachtungsspesen
- Honorare (Beratung, Vorträge)
- weitere Spesen
- Forschung und Entwicklung (Klinische Studien)
- Einzelne Überisichtsseiten existieren für Pharmaunternehmen als Geldgeber, Bildungs- und Forschungsinstutionen sowie Mediziner:Innen als Geldnehmer
- Für jedes Pharmaunternehmen exisiteren Listen für Top-Empfänger von Leistungen
- Visualisierungen exisiteren lediglich für die jährlichen Zahlungen der Pharma
Der schnellste Weg zu neuen visuellen Ideen führt meist über das digitale Zeichenbrett. Damit gelingt es mir, auch mit rudimentären Verständnis der Datenlagen, schnell spontane visuelle Ideen zu skizzieren. So lassen sich gute von schlechten, kohärente von widersinnigen, aber vor allem umsetzbare von zu ambitionierten Projekten zu unterscheiden.
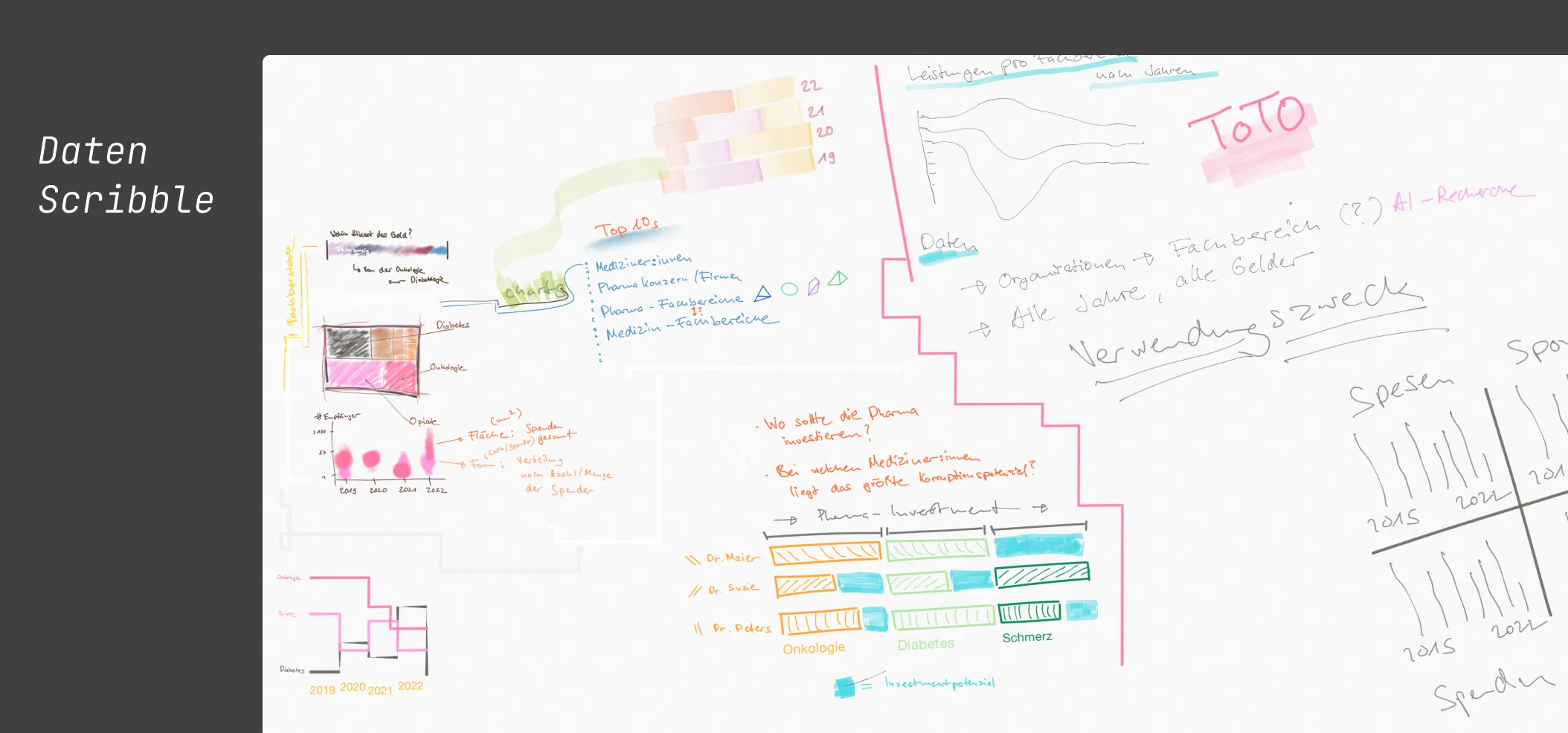
Wie schaffen wir es von der Daten-Schmiererei zum Hochglanzprodukt? Mit einer Matrix. Nichts Aussergewöhnliches, dafür aussergewöhnlich wunderlich benannt: Holup - nach einem Subreddit voll mit fraglichem, ambitioniertem, effektivem und kohärentem Humor. Im Fall von Pharmagelder.ch lernen wir:
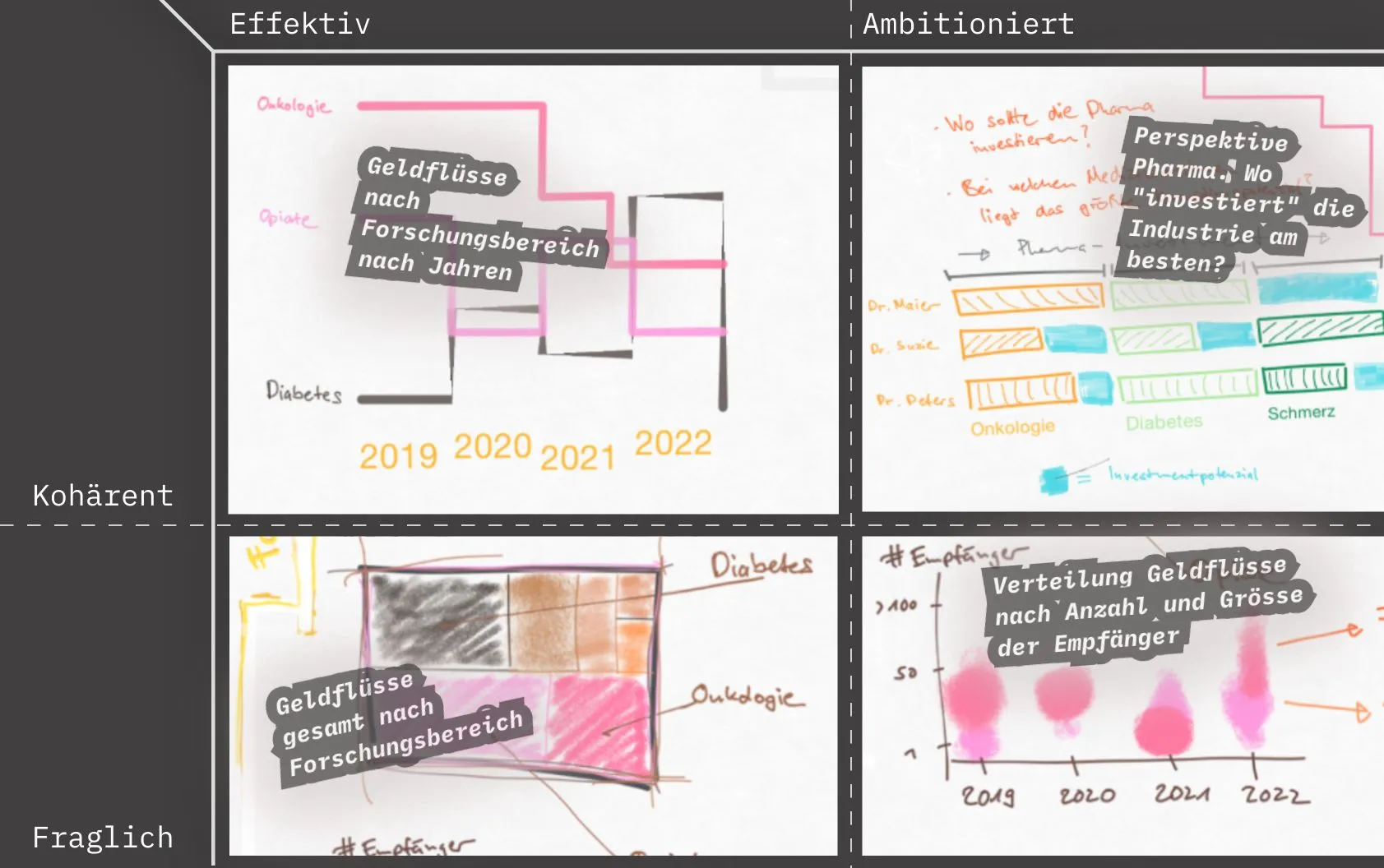
Nur wenn die Idee effektiv und kohärent ist, wird sie umgesetzt_
Kohärent aber Ambitioniert
Die Idee, den Datensatz aus der Perspektive des Geldgebers, also des Pharmaunternehmens zu betrachten, bietet zwar neue Ideen zur Visualisierung, ist aber ambitioniert. Der Ansatz erfordert ein Umdenken der Konsument:In. Die Idee, die Plattform den Pharmaunternehmen als Tool anzubieten, ihre Gelder effizienter zu verteilen, ist im besten Fall kontrovers. Damit einher geht eine Umgestaltung der Plattform und ausführliche Erklärungen, um zu zeigen, dass ein anderer Blick auch für die Konsumenten erhellend sein kann. Diese Lösung wäre zwar kohärent, aber äusserst ambitioniert und fällt somit aus dem Raster.
Effektiv aber Fraglich
Eine offensichtliche Herangehensweise ist die Visualisierung mit einer Treemap, welche die Verteilung der Geldflüsse nach Forschungsbereich darstellt. Die Konsument:In kann die Investionssummen erkennen, dem Ansatz fehlt aber Kohärenz. Weil der Konsument:In die Entwicklung der Geldflüsse verschwiegen wird, fehlt es ebenfalls an Dynamik. Der Datensatz wirkt starr und ist es ist damit fraglich, ob sie der Verbesserung der Übersichtlichkeit dient.
Ambitionert und Fraglich
Ein Ansatz wäre die Visualisierung nach Zahl der Empfänger im Verhältnis zur Grösse der Geldflüsse. Also die Frage: Wie verteilen sich die Zahlungen der Pharmaunternehmen an die Organisationen? Fördert das Pharmaunternehmen vornehmlich viele einzelne Mediziner:Innen mit kleinen Beträgen oder “sponsert” das Unternehmen grosse Organisationen mit grossen Beträgen? Es ist fraglich, ob die möglichen Erkenntnisse eine Mehrwert für die Konsumten:In liefert. Zudem würden in dieser Visualsierung eine neue Vergleichsebene eingeführt, die so in den Resultaten der Suchmaske nicht abgebildet sind. Die Folge wäre eine Restrukturierung dieser Resultate. Sehr ambitioniert.
Effektiv und Kohärent
Geldflüsse nach Forschungsbereichen und Jahren aufzuteilen, zeigt, welche Fach- bzw. Forschungsbereiche wie viel in Sponsoring und generelle Zuwendungen investieren und ob sich über die Zeit ein Marktrend im Fachbereich entwickelt. Bewusst wird hier auf die Nennung von Geldgebern und -Empfängern verzichtet. Für spezifisches Interesse in Unternehmen und Mediziner:Innen kann die Suchmaske verwendet werden. Bewertung: Dieser Ansatz is kohärent, weil eine konsequente Abstrahierung der Daten einen Überblick schafft und sie ist effektiv, weil die Visualiserung anhand einer Zeitachse einen gewohnten Mehrwert für den Konsumenten bietet. Herausforderung: Dem Datensatz fehlt die Klassifizierung nzzach Forschungsbereich, somit muss dieser nachträglich erweitert werden.
Technische Umsetzung
Techstack
API-Abfragen und Scraping:
- Technik: HTTP-Anfragen zur Datenabfrage von APIs.
- Verwendung: Abruf von Daten der Pharmaunternehmen basierend auf deren IDs; Automatisierung durch Python.
- Library:
httpxfür die Anfragen
Datenbereinigung und -verarbeitung:
- Technik: Zusammenführen, Bereinigen, Deduplizieren und Überprüfen von Datensätzen.
- Verwendung: Aggregation und Verarbeitung der Daten von Pharmaunternehmen und Geldempfängern.
- Library: Standard-Python-Methoden, Pandas.
KI-gestützte Recherche:
- Technik: Nutzung eines Large Language Models (LLM) zur Informationsrecherche und -klassifikation.
- Verwendung: Identifizierung der Hauptforschungsgebiete der Pharmaunternehmen durch Analyse von Web-Suchergebnissen.
- Library:
DSPYfür die KI-Pipeline, DuckDuckGo API für die Websuche.
Datenvisualisierung:
- Technik: Erstellung von Diagrammen und Grafiken.
- Verwendung: Visualisierung der Geldflüsse von Pharmaunternehmen nach Forschungsbereichen und Jahren.
- Library:
altairfür interaktive und statische Grafiken.
Daten von der Plattform kratzen
Im nächsten Schritt beschaffen wir die Daten für die Visualisuerng. Am einfachsten über die API. Wir navigieren gezielt von Link zu Link und zeichnen die Zugriffe auf.
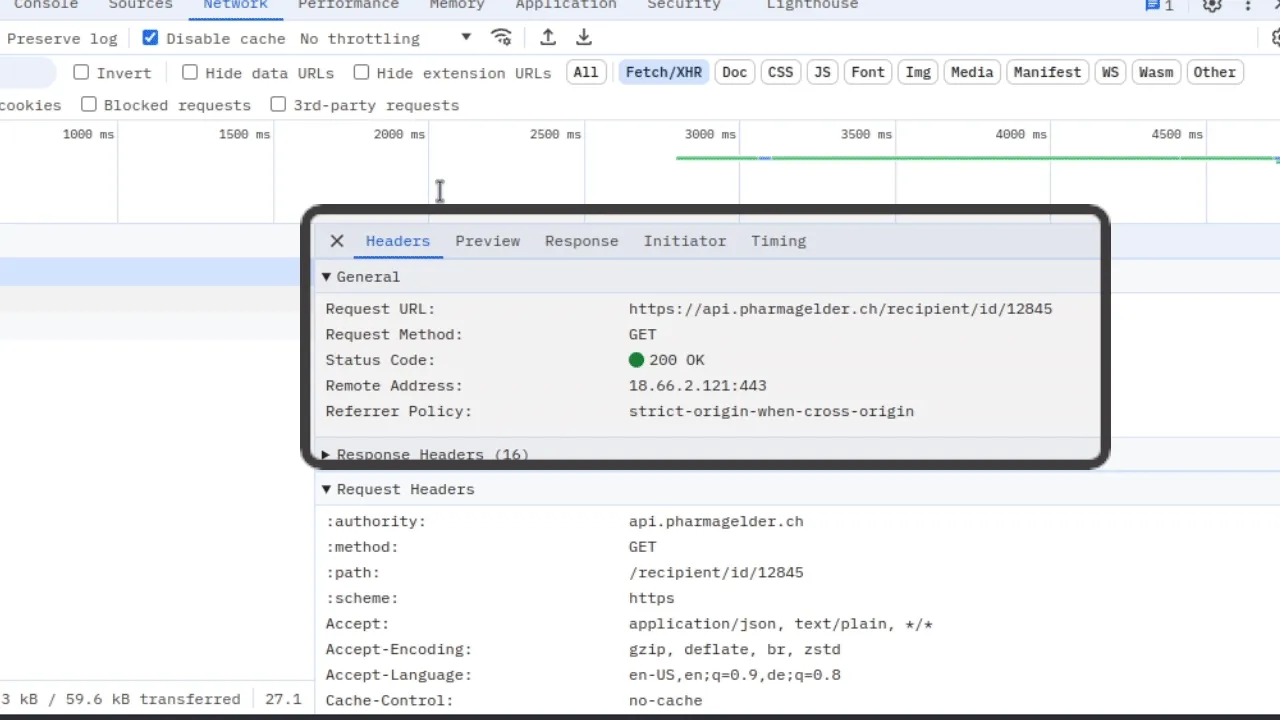
Leider gibt die API für jede Suchanfrage maximal 50 Einträge aus der Datenbank zurück. Der Parameter ‘count’ ist plafoniert. Ein möglicher Lösungsansatz ist die gezielte Suche nach der Schweizer Postleitzahl. Mit einer Liste aller PLZ sollten sollte die Abfrage vollständig sein. Ein simpler Scraper in Python automatisiert die Abfrage. Um unnötige Suchanfrage zu verhindern, arbeiten wir mit der PZZ-Liste, um den API-Endpunkt zu konstruieren und aggregieren alle empfangenen Daten.
Problem: Nach der PLZ-Abfrage der Daten von Pharmaunternehmen (pharma/search) sowie Geldempfängern (recipient/search) muss der Datensatz zusammengeführt, bereinigt, dedupliziert und geprüft werden. Der Aufwand ist für diese Post zu gross.
Da wir uns für die Visualisierung Geldflüsse nach Forschungsbereich und Jahren entschieden haben, reichen die aggregierten Daten der Pharmaunternehmen aus. Da war doch noch ein anderer Endpoint?
https://api.pharmagelder.ch/pharma/id/200
Response:
{
"status": "success",
"params": {
"pharma_id": "1"
},
"pharma": {
"id": 1,
"name": "AbbVie",
"note": null
},
"years": [
{
"year": 2022,
"sumValue": 8715006
},
{
"year": 2021,
"sumValue": 6521162
},
...
}
]Im Gegensatz zur PLZ-Methode, müssen wir lediglich die maximale Zahl der Pharmaunternehmen eruieren. Verfänglich ist, dass die API in jedem Fall eine erfolgreiche Antwort und die pharma_id sendet, auch wenn keine weiteren Daten vorhanden sind. In einer grosszügigen Schlaufe mit 200 Anfragen testen wir die Antworten des Servers. Insgesamt 78 richtige Antworten. Perfekt. Zeit für ein paar Zeilen Python.
def get_pharma_data(pharma_id):
url = f"https://api.pharmagelder.ch/pharma/id/{pharma_id}"
response = httpx.get(url, verify=True)
response.raise_for_status()
return response.json()
def pharma_page_scraper(pharma_id = 0):
json_obj = get_pharma_data(pharma_id)
while True:
try:
json_obj = get_pharma_data(pharma_id)
if json_obj.get('error'):
break
yield json_obj
except httpx.HTTPStatusError as e:
print(f"Was mit dem Server: {e}")
break
except Exception as e:
print(f"Irgendwas mit dem Code ist einfach nur schlecht! Jungejungejunge {e}")
break
pharma_id += 1
pharma_list = []
pharma_id = 0
for i in range(100):
scraper = pharma_page_scraper(pharma_id)
try:
pharma_data = next(scraper)
pharma_list.append(pharma_data)
# Zeige alle gescrapten Pharmaunternehmen und alle erflogreichen Anfragen ohne die Pharmadaten
print(pharma_data['pharma']['name'] if pharma_data.get('pharma') else pharma_data['status'])
pharma_id += 1
time.sleep(1)
except StopIteration:
print("Fertig Kratzen!")
break
except Exception as e:
print(f"Unerwartete Ausnahme. Häh?? {e}")
break
Wir sind nun stolze Kopierer aller vorhanden Jahreszahlen der Geld-Ab-flüsse aus den Pharmaunternehmen an Gesundheits-Organisationen und Mediziner:Innen in der Schweiz. Erneuten Dank an die Journalist:Innen. Was uns leider fehlt und der Datensatz, so sauber er auch ist, nicht hergibt, ist die Klassifizierung der Pharmaunternehmen nach Fach- bzw. Forschungsgebiet.
Datenputzen
| pharma | year | sumValue | |
|---|---|---|---|
| 339 | Roche Pharma AG | 2016 | 13786630 |
| 381 | Takeda Pharmaceutical | 2018 | 1344453 |
| 236 | A. Menarini AG | 2019 | 1785331 |
| 391 | UCB Pharma GmbH | 2020 | 1213409 |
| 11 | Actelion | 2015 | 2401382 |
Hilfe KI!
Was liegt näher als selber in die Recherche zu gehen und für die 78 Pharmaunternehmen die jeweiligen Fachgebiet zu finden? Eine KI zu fragen, die Arbeit für mich zu übernehmen. Klar. Dennoch ein riskantes Manöver - für den Artikel aber wagen wir den Versuch. Im Ernstfall wäre eine manuelle Überprüfung der Rechercheresultate Pflicht, oder wenigstens ein Mehrstufiges System aus Funktionen und Kontorll-KIs zur Evaluierung.
Um bei der KI-Recherche wirklich Zeit zu sparen, nutzen wir weder die ChatGPT Webapp noch das omnipräsente KI-Framework Langchain. Wir setzen auf DSPY. Wer grundlegend mit PyTorch gespielt hat, findet sich relativ schnell zu recht. Das Framework bietet etliche Features für die Optimierung einer KI-Pipeline, wir wollen für dieses Beispiel jedoch hauptsächlich vom modularen Aufbau profitieren. Wenn wir schon für die KI programmieren, dann bitte so programmatisch wie möglich.
Ich werde nicht allzu tief in die Ideen des Frameworks einsteigen. Falls Interesse an einem Beitrag zum Thema DSPY besteht, schreibt gerne an [email protected].
Erst definieren wir eine sogenannte Signature. Sie beschreibt die eigentliche Aufgabe an die KI. Übrigens verwenden wir lokal das LLM AYA von Cohere. AYA eignet sich hervorragend für Recherchen in Deutsch (und Nichtenglish).
Die Signature umfasst Input und Outputs. Die Inputs speisen wir aus dem deduplizierten Datensatz mit dem Namen des Pharmaunternehmens, der Kontext kommt aus der Onlinesuche und der Output wird vom LLM generiert.
class PharmaFieldSignature(dspy.Signature):
'''Recherchiere den Hauptmarkt des Pharmaunternehmens. Wenn kein Markt identifizierbar ist, gebe statessen 'None' zurück. Übersetze immer in die Deutsche Sprache.'''
suche_kontext = dspy.InputField(desc="Suche Resultate")
# web_kontext = dspy.InputField(desc="Resultate der DuckDuckGo-Suche")
pharma_name = dspy.InputField(desc="Der Name des Pharmaunternehmens")
pharma_markt: markt = dspy.OutputField(desc=f"Hauptmarkt des Pharmaunternehmens in einem Wort. Beispiel: markt='Onkologie'")
Zugriff auf die Suchmaschine gewähren wir dem LLM (Large Language Model) von DuckDuckGo. Eine Suchmaschine, die vorgibt, sich um die Privatsphäre zu kümmern. Wir tun es aber, weil die Suchresultate brauchbar sind und der API-Zugriff nichts kostet. Natürlich gibt es dutzende weitere Dienstleister, die besser sind, nur wollen wir wirklich für jeden Schritt ein Abo abschliessen?
def ddg_search(query: str, results:int=5) -> str:
result = DDGS().text(query, max_results=results, region="de-de")
return resultDer Kern der KI-Recherche-Pipline: das Modul. Ich zitiere aus der Dokumentation von DSPY Docs
…DSPY…separates the flow of your program (modules) from the parameters (LM prompts and weights) of each step…Each built-in module abstracts a prompting technique (like chain of thought or ReAct). Crucially, they are generalized to handle any DSPy Signature.
class PharmaField(dspy.Module):
def __init__(self):
super().__init__()
self.research_field = dspy.TypedPredictor(PharmaFieldSignature)
self.rm = ddg_search
def forward(self, pharma_name: str):
suche_kontext = ", ".join([suche['body'] for suche in self.rm(pharma_name)])
pred = self.research_field(suche_kontext=suche_kontext, pharma_name=pharma_name)
return dspy.Prediction(pharma_markt=pred.pharma_markt)Wir generieren für jedes Pharmaunternehmen in 78 Durchläufen den wichtigsten Markt, Fach- oder Forschungsgebiet. Wir bitten die KI darum, jeweils maximal einen Eintrag auszugeben. Realistischer, auch in einer klassischen Recherche, wäre es selbstverständlich, Fachgebiete z.B. nach Umsatz der Medikamente auszuwählen und ähnlich starke Märkte zu kummulieren, doch lassen wir die Aspirin in der Schachtel. Nach rund 20 Minuten und etlichen gescheiterten Versuchen davor, verschmelzen wir die Resultate des LLM mit dem abgekratzen Datensatz von pharmagelder.ch.
| pharma | year | sumValue | markt | |
|---|---|---|---|---|
| 461 | iQone Healthcare Switzerland | 2022-01-01 00:00:00 | 330640 | Onkologie |
| 167 | Galderma | 2018-01-01 00:00:00 | 300341 | Dermatologie |
| 77 | Mylan Pharma GmbH (BGP Products) | 2018-01-01 00:00:00 | 367555 | Generika |
| 239 | A. Menarini AG | 2016-01-01 00:00:00 | 1810575 | Onkologie |
Visualisierung
Im letzten Schritt wird es endlich schön. Wie Erwachsene haben wir uns für eine effektive und kohärente Visualisierung entschieden. Sie soll das Antlitz und den Umgang mit pharmagelder.ch ein wenig interessanter machen. Für die Umsetzung bleiben wir bei Python. Und für den Finish gönnen wir uns das Spiel mit Vektoren und penpot, eine Figma Alternative für UI/UX Design. Vorteile sind der offene Quellcode und eine einmalige Kompatibilität zum Vektorenstandard SVG.
In Python nutzten wir altair, um schnell mit diversen Visualisuerngsstandards zu spielen. Wir starten mit Balken der grössten Geldgebern in der Schweizer Gesundheitsindustrie.
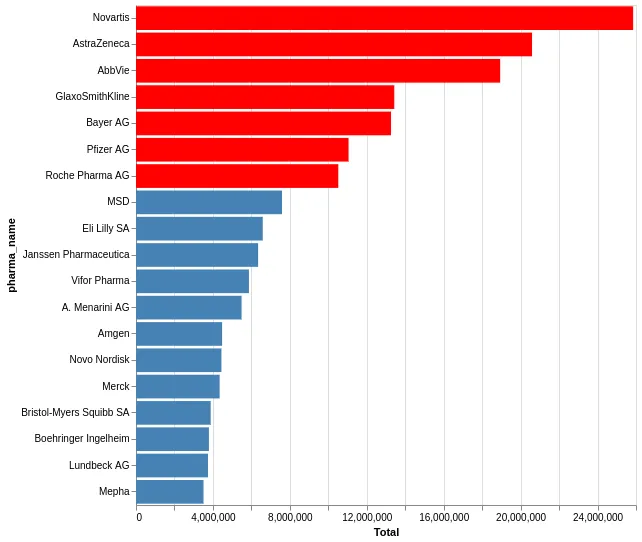
alt.Chart(pharma_gelder_fachgebiete).mark_bar().encode(
alt.X("Total:Q"),
alt.Y(
"pharma_name:N", sort=alt.EncodingSortField(field="Total", order="descending")
),
# color="Fachgebiet 1",
color=alt.condition(
alt.datum.Total > 10000000,
alt.value("red"),
alt.value("steelblue"),
),
).transform_window(
rank="rank(Total)", sort=[alt.SortField("Total", order="descending")]
).transform_filter(
alt.datum.rank < 20,
).properties(width=500, height=500)Nach einigen Versuchen sind die gewünschte Grafik gefunden.


Alle Nebenwirkungen auf einen Blick
Nicht nur Penpot mag SVG, die altair Library eignet sich ausgezeichnet für den Grafikexport. Manuell lässt sich die Datenvisualisierung schnell in Form und Stil anpassen oder gar animieren oder automatisch erzeugen oder direkt von eine KI optimieren, verschönern oder verstümmeln. Ruhig Brauner! Das Pferd ist eingeritten. Liebe Turfist:Innen, liebe Pharmazeut:Innen, so sieht das Pferd nach dem Doping aus:

Merci.
Disclaimer
Vizbeth war an einem anderen Projekt des Beobachters (Teil des Ringier-Verlages) beteiligt.